Để xử lý những tài liệu với cấu hình và nửa cấu hình, những căn nhà cải cách và phát triển tiếp tục dùng những loại dụng cụ tàng trữ tài liệu bên trên Hadoop. Cụ thể này là Hive – một hạ tầng tài liệu hỗ trợ ngữ điệu truy vấn linh động hùn xử lý tài liệu hiệu suất cao. Hãy nằm trong BKHOST lần hiểu cụ thể về cấu hình và chính sách của Hive nhập nội dung bài viết tiếp sau đây.
Hive là gì?

Bạn đang xem: beehive la gi
Hive là một trong dụng cụ tàng trữ tài liệu được tổ chức thực hiện dựa vào Hadoop Distributed File System. Hệ thống này tương hỗ Hive triển khai nhiều việc làm không giống nhau như gói gọn tài liệu, truy vấn quan trọng và phân tách khối tài liệu lớn.
Hive với những Điểm lưu ý nổi trội nào?
Một số Điểm lưu ý cần thiết của Hive bao gồm:
- Tất cả những bảng và hạ tầng tài liệu của Hive điều được tổ chức thực hiện trước nhằm tàng trữ tài liệu.
- Kho tài liệu của Hive chỉ phụ trách quản lý và vận hành những tài liệu với cấu hình được tàng trữ nhập bảng của chính nó.
- Framework Hive với tài năng tối ưu hóa những truy vấn hùn nâng cấp hiệu suất rất tuyệt.
- Hive dùng ngữ điệu được tổ chức thực hiện dựa vào SQL hùn giản dị hóa thiết kế Map Reduce. Bên cạnh đó, nó còn dùng một trong những nghệ thuật nhập RDB như bảng, sản phẩm, cột và Schema.
- Lập trình của Hadoop sinh hoạt bên trên Flat File được cho phép Hive rất có thể dùng cấu hình folder nhằm phân vùng tài liệu. Như vậy hùn nâng cấp hiệu suất so với một trong những truy vấn.
- Metastore là bộ phận cần thiết của Hive sinh hoạt nhập RDB được dùng nhằm tàng trữ vấn đề Schema. Người sử dụng rất có thể tương tác với Hive trải qua GUI trang web hoặc JDBC.
- CLI tương hỗ người tiêu dùng ghi chép những truy vấn Hive tự HQL.
- Tương tự động như SQL, HQL cũng khá được dùng nhằm phân tách những tài liệu. Chẳng hạn như với truy vấn Select * from hiển thị toàn bộ những bạn dạng ghi với nhập bảng Hive.
- Hive tương hỗ tư định hình tệp phổ cập này là TEXTFILE, SEQUENCEFILE, ORC và RCFILE.
- Hive dùng hạ tầng tài liệu Derby nhằm tàng trữ siêu tài liệu cá thể và dùng MYSQL nhằm tàng trữ siêu tài liệu công nằm trong.
Các Điểm lưu ý không giống của Hive
- HQL và SQL sinh hoạt bên trên hạ tầng tài liệu truyền thống lâu đời còn truy vấn Hive sinh hoạt bên trên hạ tầng của Hadoop.
- Việc thực ganh đua những truy vấn Hive tương tự động như việc tạo nên những Job MapReduce tự động hóa.
- Hive tương hỗ phân vùng và Bucket được cho phép người tiêu dùng rất có thể truy xuất tài liệu đơn giản và dễ dàng nhập quy trình truy vấn của sản phẩm khách hàng.
- Hive được cho phép người tiêu dùng rất có thể tùy chỉnh UDF nhằm mục đích vô hiệu hóa và thanh lọc những tài liệu.
Hive đối với RDB
Hive được tổ chức thực hiện những công dụng mới mẻ nhưng mà RDB không tồn tại. Chẳng hạn như Hive rất có thể truy vấn và xử lý tài liệu với độ dài rộng rộng lớn tính tự petabyte một cơ hội linh động và hiệu suất cao. Một số điểm không giống thân thích Hive và RDB như sau:
- RDB là Schema on READ and Schema on Write sinh hoạt bằng phương pháp tạo nên bảng được cho phép người tiêu dùng triển khai nhiều việc làm như chèn, update và sửa đổi.
- Hive là Schema on READ only ko tương hỗ những thao tác như RDB bởi vì nó là truy vấn điều khiển xe trên nhiều Data Node.
- Hive cũng tương hỗ quy mô READ Many WRITE Once được cho phép người tiêu dùng rất có thể update những bảng tài liệu nhập phiên bạn dạng Hive tiên tiến nhất.
Cấu trúc của Hive
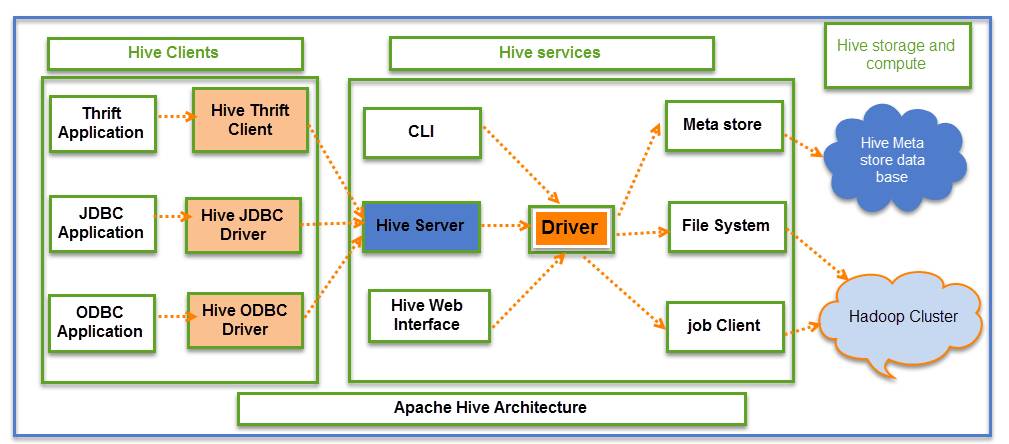
Cấu trúc của Hive bao gồm với thân phụ bộ phận chủ yếu này là Hive Client, Hive Service và Hive Storage and Computing. Cụ thể như sau:
Hive Client
Với từng một loại phần mềm thì Hive tiếp tục hỗ trợ một trình tinh chỉnh ứng với nó. Chẳng hạn như so với những phần mềm dựa vào Thrift thì Hive tiếp tục hỗ trợ phần mềm Thrift Client nhằm tương tác, hoặc với phần mềm của Java thì Hive hỗ trợ trình tinh chỉnh JDBC.
Hive Service
Hive Service tương hỗ người tiêu dùng đơn giản và dễ dàng tương tác với Hive. Cụ thể, nó được cho phép người tiêu dùng triển khai những hành động tương quan cho tới truy vấn nhập Hive. Tương tự động như Hive Service, CLI cũng khá được dùng nhằm tương hỗ DDL.
Các trình tinh chỉnh nhập Hive Service rất có thể tương tác với JDBC, ODBC và những phần mềm Client không giống. Nó với trọng trách xử lý những đòi hỏi của phần mềm bên trên Meta Store và Field System.
Xem thêm: Bongdainfo: Bí kíp cá cược kèo bóng đá hiệu quả cùng chuyên gia
Hive Storage and Computing
Một số Hive Service như Meta store, File system và Job Client thứu tự tiếp xúc với Hive Storage và triển khai những hành vi sau:
- Thông tin cậy siêu tài liệu bên trên những bảng của Hive được tàng trữ nhập Metadata Information.
- Các thành phẩm truy vấn và tài liệu nhập bảng của Hive được tàng trữ nhập Hadoop Cluster bên trên HDFS.
Quy trình Job Execution
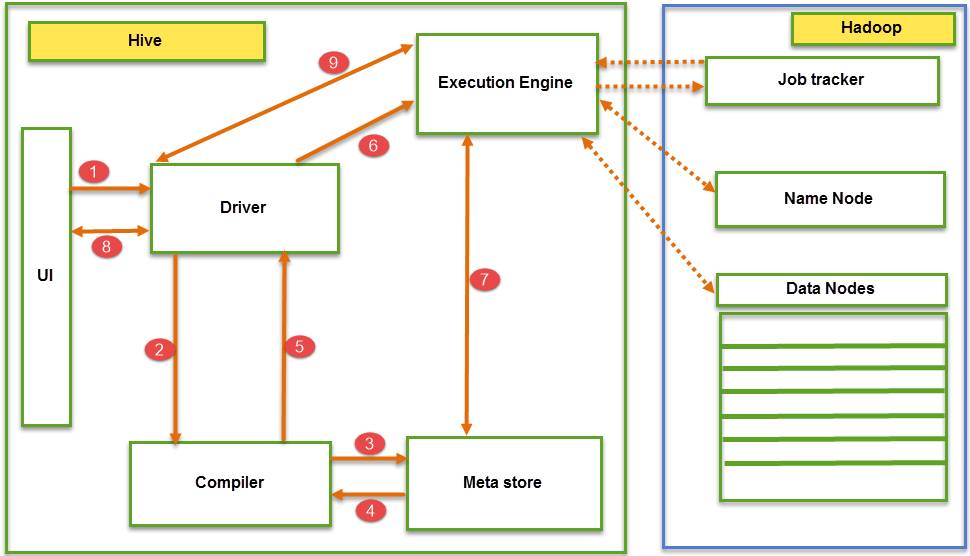
Quá trình thực ganh đua Job Execution nhập Hive bao hàm quá trình sau:
- Thực ganh đua truy vấn kể từ UI.
- Trình tinh chỉnh tương tác với trình biên dịch nhằm nhận plan thực ganh đua truy vấn và tích lũy vấn đề siêu tài liệu.
- Trình biên dịch tổ chức thực hiện plan mang đến việc làm được thực ganh đua và tương tác với Meta Store nhằm nhận đòi hỏi siêu tài liệu.
- Meta Store gửi vấn đề siêu tài liệu mang đến trình biên dịch.
- Trình biên dịch tương tác với trình tinh chỉnh nhằm triển khai những truy vấn theo đòi plan được khuyến nghị.
- Trình tinh chỉnh gửi plan thực ganh đua mang đến dụng cụ thực ganh đua.
- Hive và Hadoop triển khai xử lý truy vấn dựa vào EE. Còn so với DFS thì EE với trọng trách như sau:
- EE tiếp cận Name Node tiếp sau đó là Data Node nhằm nhận những độ quý hiếm được tàng trữ nhập bảng.
- EE tích lũy những bạn dạng ghi tài liệu thực tiễn kể từ Data Node và lấy vấn đề siêu tài liệu mang đến truy vấn kể từ Name Node.
- EE với tài năng tiếp xúc hai phía với Meta Store nhập Hive tương hỗ những sinh hoạt DDL như CREATE, DROP, ALTERING Table và hạ tầng tài liệu được triển khai.
- EE tương tác thứu tự với những Daemon Hadoop như Name Node, Data Node và Job Tracker nhằm triển khai những truy vấn bên trên Hadoop.
- Thu thập những thành phẩm kể từ trình tinh chỉnh.
- Gửi thành phẩm cho tới dụng cụ thực ganh đua, tiếp sau đó những tài liệu kể từ Data Node sẽ tiến hành fake cho tới EE. Cuối nằm trong, EE tiếp tục trả thành phẩm mang đến trình tinh chỉnh và UI.
- Hive tương tác với khối hệ thống tệp Hadoop và những Daemon của chính nó trải qua dụng cụ thực ganh đua. Trong số đó, ký hiệu mũi thương hiệu chấm nhập tiến độ Job Execution thể hiện tại việc dụng cụ thực ganh đua tiếp xúc với Daemon Hadoop.
Các chính sách phổ cập của Hive
Hive hiện tại với nhì chính sách sinh hoạt phổ cập được dùng tối đa lúc này là Local và Map reduce. Trong số đó, nhì chính sách này được phân biệt bằng phương pháp phụ thuộc vào độ dài rộng của Data Node nhập Hadoop. Bên cạnh đó, tùy nhập tình huống nhằm dùng Local và Map reduce. Cụ thể như sau:
Local mode
- Local mode sinh hoạt nhập tình huống Hadoop được thiết lập ở chính sách ảo và với Data Node.
- Local mode phù phù hợp với những tài liệu với độ dài rộng nhỏ rộng lớn đối với số lượng giới hạn tàng trữ của sever toàn thể.
- Local mode rất có thể xử lý những tập luyện tài liệu một cơ hội nhanh gọn và hiệu suất cao.
Map reduce mode
- Map reduce mode khả ganh đua nhập tình huống Hadoop có rất nhiều Data Node và những tài liệu được phân phối trên rất nhiều Node không giống nhau.
- Map reduce mode rất có thể xử lý con số rộng lớn tập luyện tài liệu với hiệu suất cao. Bên cạnh đó, nó còn hỗ trợ thực ganh đua tuy nhiên song những truy vấn bên trên Hadoop một cơ hội đơn giản và dễ dàng.
Trong Hive, chính sách Map Reduce và chính sách Local được thiết lập bằng phương pháp mua sắm đặt: SET mapred.job.tracker=local;. Trong số đó, kể từ phiên bạn dạng Hive 0.7 vẫn tương hỗ một trong các nhì chính sách bên trên nhằm mục đích thuyên giảm việc làm của Map Reduce nhập chính sách.
Hive Server2 (HS2) là gì?
HiveServer2 (HS2) là một trong loại hình mẫu sever được dùng với những việc làm như sau:
Xem thêm: tiểu thuyết lãng mạn phương tây 18
- HiveServer2 được cho phép Client kể từ xa xăm triển khai những truy vấn so với Hive nhập Hadoop.
- HiveServer2 rất có thể tích lũy những thành phẩm của truy vấn đang được thực ganh đua trước cơ.
- Các phiên bạn dạng HiveServer2 vừa mới được bổ sung cập nhật những công dụng nâng lên dựa vào Thrift RPC như Multi-client concurrency và Authentication.
Tổng kết
Hive là một trong trong mỗi dụng cụ tàng trữ và xử lý những truy vấn tài liệu bên trên Hadoop cực tốt lúc này. Không chỉ tương hỗ triển khai những sinh hoạt DDL nhưng mà nó còn hỗ trợ ngữ điệu truy vấn linh động như HQL. Hy vọng trải qua bài bác share này độc giả vẫn bắt được những vấn đề tương quan cho tới cấu hình và chính sách Hive hao hao với những cách thức tổ chức thực hiện nó hiệu suất cao nhất.
Nếu còn gặp gỡ bất kể vướng vướng gì về Hive, hãy nhằm lại ở mặt mày comment bên dưới, BKHOST tiếp tục vấn đáp các bạn nhập thời hạn sớm nhất có thể.
P/s: quý khách hàng cũng rất có thể truy vấn nhập Blog của BKHOST nhằm hướng dẫn thêm những nội dung bài viết share kỹ năng về thiết kế, quản lí trị mạng, trang web, tên miền, hosting, vps, server, tin nhắn,… Chúc các bạn thành công xuất sắc.











Bình luận